
Python Tutorial: Web Scraping NBA Regular Season Excitement and Tension
Introduction
For my upcoming project analyzing whether the NBA regular season has gotten less exciting, I used two key metrics: excitement, which measures how much a win probability graph moves over the course of the game, and tension, which measures how close a win probability graph is to 50/50.
This post will detail how I used Python to scrape excitement and tension data for every regular season game hosted on Inpredictable.
Inpredictable’s Website
First, we can start at the home page for NBA’s top games by excitement and tension.
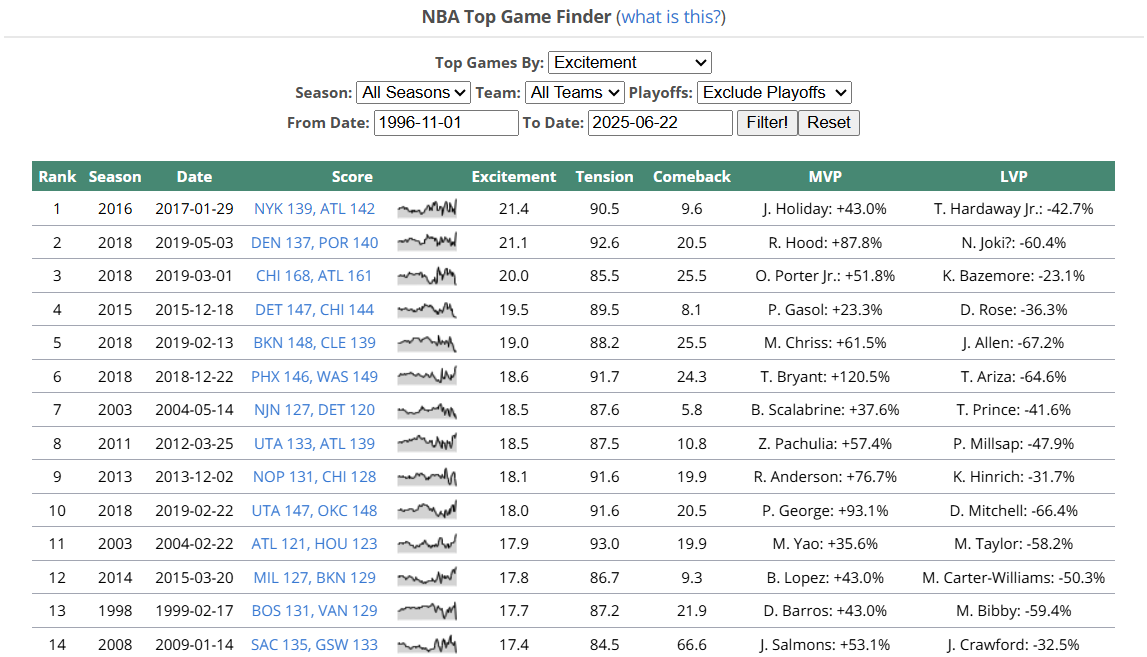
Looking at this page, there are several key observations:
- The results are stored in a table, with the max rows being 25.
- Each row stores a single game, recording the season, date, score, excitement, and tension.
- The dates run from November 1, 1996 to June 22, 2025.
- There is an option filter to include or exclude playoffs.
Based on these observations, if we wanted to get data for every single game, we’d have to search extensively through each date regular season games were played and scrape the data table stored.
If we hit “Exclude Playoffs” and pick a random date (November 1st, 2023), we end up on this page:
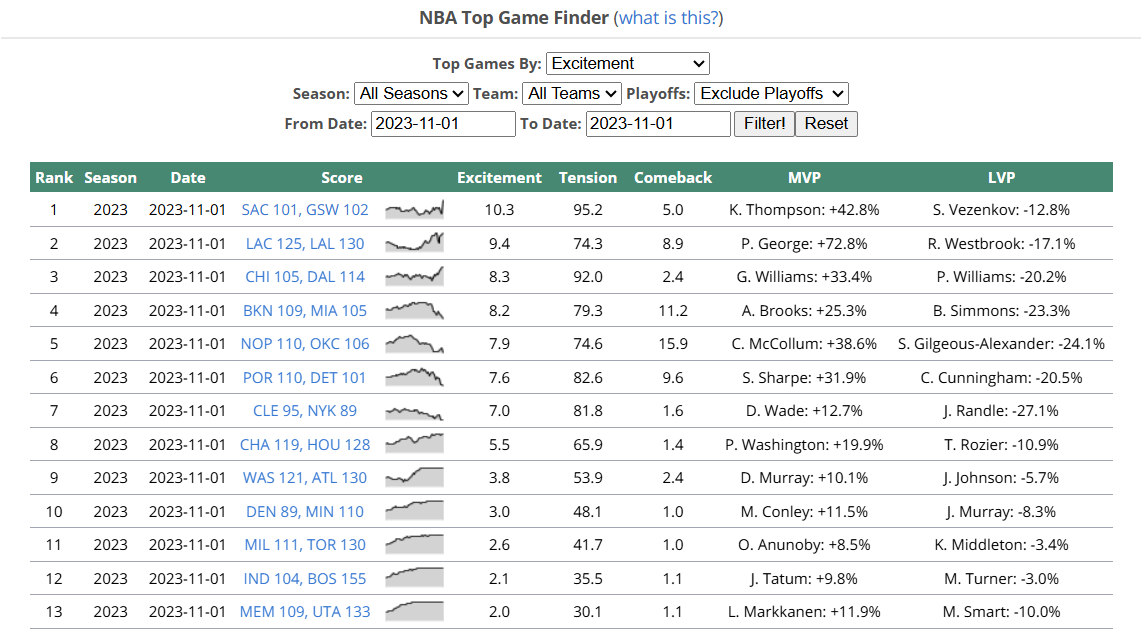
Two more observations:
po=0is the setting which excludes playoff games.- To filter to a specific date, we need to set
frdtandtodtto the same date, in the YYYY-MM-DD format.
Now that we understand the website, we are ready to start web scraping!
Scraping a Single Page
Using our November 1st, 2023 day as an example, we can read information from the page by sending a request. Since we know that the results are stored in a table, we can use pd.read_html() to
read the HTML table into a dataframe. StringIO(r.text) transforms our webpage, stored as r, into a file-like object, so that it is compatible with the read_html command. read_html also
produces a list. Since there is only one table, we can obtain our table by taking the first item in this list. Since we are only interested in the values for excitement and tension, we can access them using
game_table['Excitement'] and game_table['Tension']. list(game_table['Excitement'].values) gives us the excitements as a list.
import requests
import pandas as pd
from io import StringIO
url = 'https://stats.inpredictable.com/nba/topGame.php?sort=ei&season=ALL&team=ALL&po=0&frdt=2023-11-01&todt=2023-11-01'
r = requests.get(url)
all_tables = pd.read_html(StringIO(r.text))
game_table = all_tables[0]
excitement_values = list(game_table['Excitement'].values)
tension_values = list(game_table['Tension'].values)
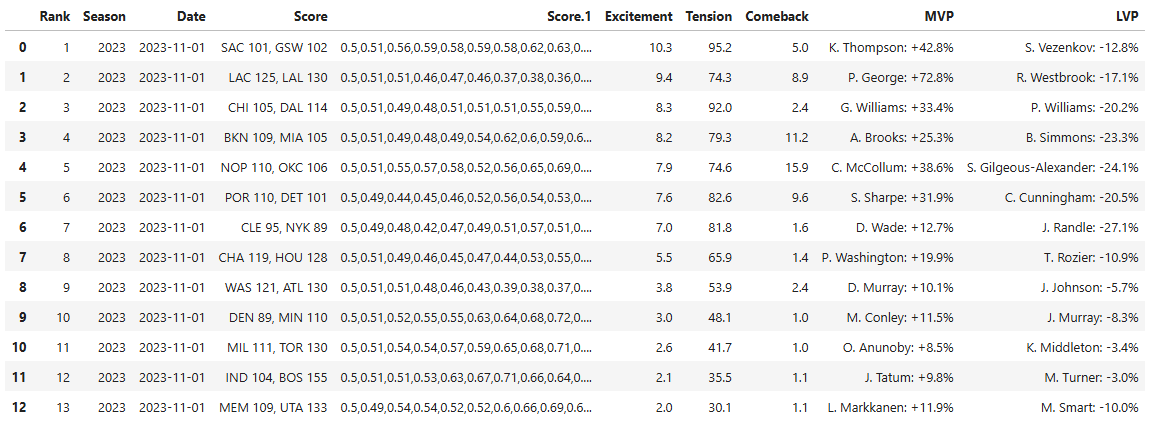
The results of this table are displayed:
Scraping Multiple Days
Now that we got the results from one day, we want to write a script that will help us scrape every regular season game. To start, we’ll want to create a list of dates that we can iterate through. Recall
that the earliest date in the data was November 1, 1996. For the end date, we can use April 13, 2025, which is the last day of the 2025 NBA regular season. We use pandas’ date_range command to create a list of
datetime64 objects in our specified range, with freq='d' indicating that we need daily intervals.
sdate = date(1996, 11, 1)
edate = date(2025, 4, 13)
nba_dates = pd.date_range(sdate,edate,freq='d')
With this list, we can interate through each day and scrape each day’s information. Note that some days, there might not be any games, so we want to include an if statement to check for any dates.
If we check the Date column and it has a length of 0, then we’ll know
for date in nba_dates:
date_str = str(date)[0:10]
url = f'https://stats.inpredictable.com/nba/topGame.php?sort=ei&season=ALL&team=ALL&po=0&frdt={date_str}&todt={date_str}'
r = requests.get(url)
all_tables = pd.read_html(StringIO(r.text))
game_table = all_tables[0]
table_dates = list(game_table['Date'].values)
if len(table_dates) > 0:
excitement_values = list(game_table['Excitement'].values)
tension_values = list(game_table['Tension'].values)
We are almost done! One thing we haven’t done yet is actually store the excitement and tension values anywhere. There are many options you can choose – personally I wanted to be able to store the final results in a
JSON format. I want to be able to analyze excitement and tension by season, as well as date. Using the previous example date of November 1st, 2023, I would want to access the excitement and tension via season, and date,
in the format excitement[2023][2023-11-01]. To do this, I create two dictionaries of dictionaries. The key of the outer dictionary will be the seasons, from 1996 to 2024. Then for each season, the keys will be the dates
in that season, so that we can access excitement and tension for a specific day during that season.
excitement = {}
tension = {}
for year in range(1996, 2025):
excitement[year] = {}
tension[year] = {}
Now that we have a place to store the data, we can put everything together. I also added a section to write our data, so that we can access our results again in the future, rather than scrape everything all over again.
import pandas as pd
import numpy as np
import requests
from io import StringIO
from datetime import date, timedelta
import json
sdate = date(1996, 11, 1) # start from oldest date in inpredictable databse
edate = date(2025, 4, 13) # end of 2025 nba regular season
nba_dates = pd.date_range(sdate,edate-timedelta(days=1),freq='d')
excitement = {} # Excitement of every game on a given date
tension = {} # Tension of every game on a given date
for year in range(1996, 2026):
excitement[year] = {}
tension[year] = {}
# For all dates, collects excitement and tension of all games on that day
for date in nba_dates:
date_str = str(date)[0:10]
url = f'https://stats.inpredictable.com/nba/topGame.php?sort=ei&season=ALL&team=ALL&po=0&frdt={date_str}&todt={date_str}'
r = requests.get(url)
all_tables = pd.read_html(StringIO(r.text)) # this parses all the tables in webpages to a list
game_table = all_tables[0]
table_dates = list(game_table['Date'].values)
if len(table_dates) > 0: # check that there are games this day
excitement[int(game_table['Season'][0])][table_dates[0]] = list(game_table['Excitement'].values) # store all excitements this day using season and date as keys
tension[int(game_table['Season'][0])][table_dates[0]] = list(game_table['Tension'].values) # store all tension this day using season and date as keys
if date_str[8:10] == '01': # Prints an update for progress on each month
print(f'added {table_dates[0]}')
# add all excitement and tension data into JSON files
with open('excitement.json', 'w') as fp:
json.dump(excitement, fp)
with open('tension.json', 'w') as fp:
json.dump(tension, fp)
Conclusion
In this Python tutorial, we learned how to send requests to websites, and read the table information stored using pandas. We also learned how to store these values in a JSON format, as well as how to write a loop
to obtain data from multiple pages. You can also access my Excitement and Tension files instead of scraping, to do your own analysis!
Warning: Some sites may block you from sending requests entirely or if you send too many. It is best practice to use an API if available (unfortunately I don’t know of one for Inpredictable), or send requests intermittently. To learn about web scraping best practices, check out some resources.